🧬Code Architecture#
Overall Architecture of genesis_lr#
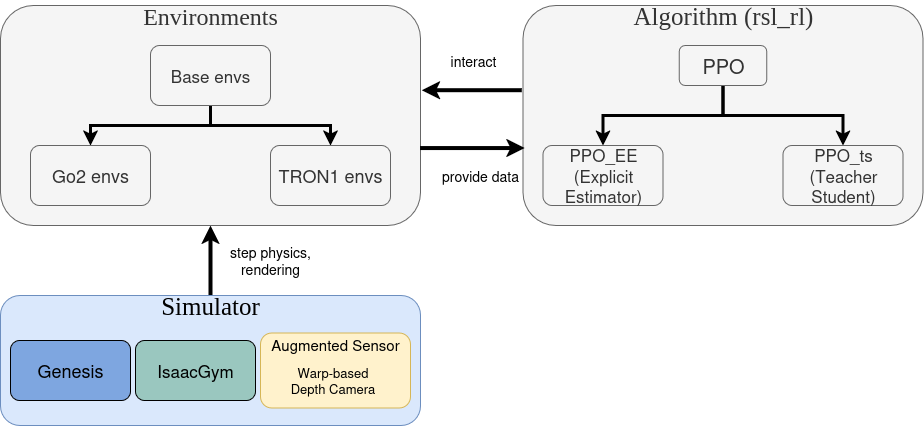
The whole project can be separated into 3 parts: simulator, environments and algorithms.
Simulator (legged_gym/simulator)#
The simulator layer provides unified api for different simulators, including IsaacGym and Genesis. Users can choose either simulator to use for training.
Apart from sensors embedded in simulators, we implemented external augmented sensors, mainly for IsaacGym. Currently, we provide warp-based depth camera sensors to accelerate rendering in IsaacGym. Compared to the embedded depth camera in IsaacGym, warp-based depth camera can provide 2-3x faster rendering speed during headless training.
Environments (legged_gym/envs)#
Environments are where the agent collects data and receives reward signal from. Users can define the task and the dynamics. Environments follow the inheritance style. Users can define new environment classes inheriting base classes (legged_robot.py). Configuration (config) files in environments are responsible for storing parameters and settings for environments.
Algorithms (rsl_rl)#
Algorithms define reinforment learning algorithms used in training. Currently we implement PPO (Proximal Policy Optimization), SPO (Simple Policy Optimizatino) and several training architecture based on them (Explicit Estimator, Teacher Student, Cocurrent TS, DreamWaQ).
Sim2Sim#
Sim2Sim (Simulation-to-Simulation) validation is a critical step in the development pipeline that validates trained policies across different physics simulators before real-world deployment. This process helps identify overfitting to simulator-specific artifacts and ensures the policy’s robustness.
Why Sim2Sim Matters#
Training policies in a single simulator can lead to exploitation of physics engine idiosyncrasies. For example, a policy trained exclusively in IsaacGym might exploit specific contact handling behaviors that differ in Genesis or real hardware. By validating across simulators, you can:
Detect overfitting to specific contact models or friction approximations
Identify dependency on particular numerical integration schemes
Ensure consistent behavior across different physics backends
Increase confidence before Sim2Real transfer
Training Loop Architecture#
The training loop in OnPolicyRunner follows a clear four-phase pattern:
1. Initialization Phase#
The runner initializes three core components in sequence:
Environment → Actor-Critic Network → Algorithm → Rollout Storage
First, the environment provides observation and action space specifications. The runner then instantiates the actor-critic network using the configured policy class (standard or recurrent). The PPO algorithm wraps this network with optimization logic. Finally, rollout storage allocates buffers for collecting experience.
2. Rollout Collection Phase#
During each iteration, the runner collects num_steps_per_env transitions:
for step in range(num_steps_per_env):
actions = alg.act(obs, critic_obs) # Policy forward pass
obs, rewards, dones, infos = env.step(actions) # Environment step
alg.process_env_step(rewards, dones, infos) # Store transition
This phase operates under torch.inference_mode() for efficiency. Episode statistics are tracked using rolling buffers that capture reward sums and episode lengths for completed episodes.
3. Learning Phase#
After collecting rollouts, the algorithm performs the update:
alg.compute_returns(critic_obs) # Compute advantages using GAE
mean_value_loss, mean_surrogate_loss = alg.update() # PPO update
The update runs multiple epochs over mini-batches of the collected data, computing clipped surrogate losses and value function losses. Learning rate scheduling based on KL divergence occurs here.
4. Logging and Checkpointing Phase#
Metrics are logged to TensorBoard (and optionally WandB):
Performance metrics: FPS, collection time, learning time
Loss metrics: Value loss, surrogate loss, entropy
Policy metrics: Mean action noise standard deviation
Episode metrics: Mean reward, episode length
Checkpoints are saved at configured intervals containing model weights, optimizer state, and iteration count.
Checkpoint File Structure#
Checkpoints are saved as PyTorch .pt files in the log directory:
logs/
└── experiment_name/
├── model_50.pt # Checkpoint at iteration 50
├── model_100.pt # Checkpoint at iteration 100
└── exported/
└── policy.pt # JIT-exported policy for deployment
Each checkpoint contains:
Key |
Contents |
|---|---|
|
Actor-critic network weights |
|
Adam optimizer state |
|
Current learning iteration |
|
Optional metadata dictionary |
Loading a checkpoint restores both the model weights and optimizer state, allowing seamless resumption of training:
runner.load("model_500.pt", load_optimizer=True)
runner.learn(num_learning_iterations=1000) # Continue from iter 500
Component Interaction Overview#
The data flow between components follows a circular pattern:
┌─────────────────┐ observations ┌──────────────────┐
│ Environment │ ←──────────────────→ │ Actor-Critic │
│ (legged_gym) │ actions │ Network │
└────────┬────────┘ └────────┬─────────┘
│ │
│ states, rewards, dones │ policy
│ │ distribution
↓ ↓
┌──────────────────────────────────────────────────────────┐
│ Algorithm (PPO) │
│ ┌────────────────────────────────────────────────────┐ │
│ │ Rollout Storage │ │
│ │ stores: obs, actions, rewards, values, log_probs │ │
│ └────────────────────────────────────────────────────┘ │
│ │
│ compute_returns() → update() → optimize step │
└──────────────────────────────────────────────────────────┘
Environment Interface: Provides step(), reset(), and get_observations() methods. Returns batched tensors for all parallel environments.
Actor-Critic: Implements act() (training mode with exploration noise) and act_inference() (deterministic inference mode). Handles both observation processing and value estimation.
Algorithm: Orchestrates the learning process. Calls init_storage() to prepare buffers, process_env_step() to store transitions, compute_returns() for advantage estimation, and update() for gradient steps.
Storage: Maintains circular buffers for the current rollout. Computes returns and advantages when queried, handles mini-batch sampling for updates.
Inference Flow for Sim2Sim Testing#
The play.py script handles Sim2Sim validation:
Configuration Override: Reduces environment count for visualization, enables debug mode, adjusts terrain for testing
Policy Loading: Restores model from checkpoint and switches to evaluation mode
Export Phase: Converts trained policy to JIT format for cross-platform compatibility
Interaction Loop: Runs policy in environment with real-time visualization
Different task types (teacher-student, explicit estimator, etc.) have specialized observation handling and export logic:
if task_type == "ts":
actions = policy(obs_buf, obs_history) # Uses history buffer
elif task_type == "ee":
actions = policy(estimator_features) # Uses estimated states
else:
actions = policy(obs_buf) # Standard observation
Best Practices for Sim2Sim Validation#
Match observation spaces: Ensure all simulators provide identical observation formats
Normalize consistently: Use the same normalization statistics across simulators
Verify action ranges: Confirm joint limits and action scaling match
Test terrain variations: Validate on different terrain types to ensure generalization
Monitor episode lengths: Significant differences may indicate physics discrepancies
Compare contact behaviors: Foot contact patterns are often simulator-specific