🧑🏫🧑🏫 Teacher-Student Framework#
In Walk These Ways, we know that through tuning robot behaviors, we can let a policy trained on flat ground traverse some difficult terrains (like small curbs and stairs). It indicates generalization ability of the policy since it has been only trained on flat ground and data concerning complex terrains are not included in the training dataet. However, to achieve better stability and traversability on complex terrains, training on terrains are inavoidable. But as introduced in deploy_to_real_robot, just a simple network that gets robot state feedback of one time step is not enough. Actually, if you use RNN or stack observation of multiple time steps, the policy will gain better ability to adapt to terrains. However, we still need some mechanism to effectively extract key information from observation history and endow the policy with better understanding of the robot and the surrounding environment.
Teacher-Student Framework#
As one of the pioneer of RL-based control on legged robots, RSL from ETH zurich has proposed a series of works to push the limit of quadruped robots on complex terrains. The one introduced here is teacher-student framework.
Intuitively, we understand that with privilege information(base_lin_vel, friction_ratio, added_mass, base_com_bias e.t.c) the locomotion problem can be seen as MDP(Markov Decision Process) instead of POMDP(Partially Observable Markov Decision Process). The policy can find better solution with more useful information. However, in real world, privilege information is not observable. But instead, it can be estimated. The key insight of teacher-student framework is that privilege information can be estimated from observation history. The simplified diagram of teacher-student is shown as below, where \(x_t\) is privileged information, \(o_t^H=[o_t, o_{t-1},...,o_{t-H+1}]\) is observation history with length of H steps, \(l_t\) is encoded latent vector from teacher encoder, \(\hat{l}_t\) is predicted latent vector from student encoder, \(a_t\) is the action, \(s_t\) is the state of the environment, \(\hat{V}_t\) is the estimated value from the critic.
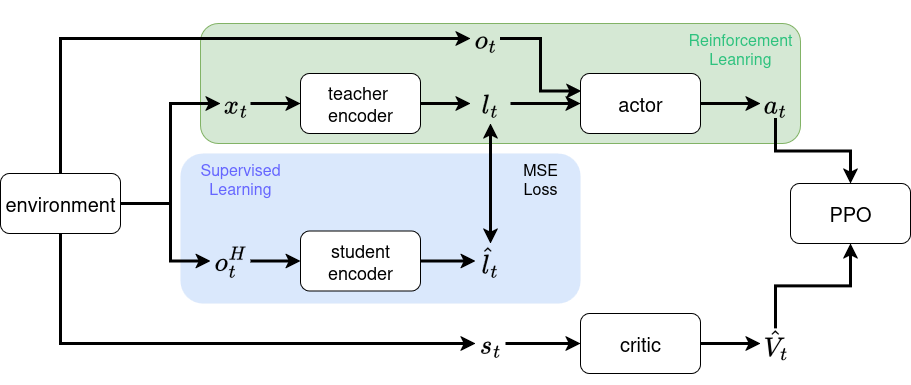
The privilege encoder(or teacher encoder) encodes privilege information into latent space with the same dimension. The history encoder(or student encoder) infers latent vectors of privilege information from observation history. The policy observes current observation and latent vectors, and outputs actions.
The original teacher-student framework is a two-stage training framework, where encoder and actor are coupled. The teacher encoder and teacher policy are trained in the first stage, and the student encoder and student policy are trained in the second stage. To simplify the training process, RMA proposed to decouple the encoder and policy, only requiring training student encoder in the second stage. Furthermore, RLvRL proposed to achieve one-stage training by concurrently conducting reinforcement learning and supervised learning. The above diagram is the same as the method of RLvRL.
Implementation#
We implement a one-stage teacher-student training framework based on RLvRL. The core modification compared to standard actor-critic is in actor_critic_ts.py and ppo_ts.py. In actor_critic_ts.py, we add privilege encoder and history encoder as neural network modules.
# actor_critic_ts.py
# Privilege encoder
privilege_encoder_layers = []
privilege_encoder_layers.append(
nn.Linear(num_privilege_encoder_input, privilege_encoder_hidden_dims[0]))
privilege_encoder_layers.append(activation)
for l in range(len(privilege_encoder_hidden_dims)):
if l == len(privilege_encoder_hidden_dims) - 1:
privilege_encoder_layers.append(
nn.Linear(privilege_encoder_hidden_dims[l], num_latent_dims))
else:
privilege_encoder_layers.append(nn.Linear(
privilege_encoder_hidden_dims[l], privilege_encoder_hidden_dims[l + 1]))
privilege_encoder_layers.append(activation)
self.privilege_encoder = nn.Sequential(*privilege_encoder_layers)
# History encoder
self.history_encoder_type = history_encoder_type
history_encoder_layers = []
if history_encoder_type == "MLP":
history_encoder_layers.append(
nn.Linear(num_history_encoder_input, history_encoder_hidden_dims[0]))
history_encoder_layers.append(activation)
for l in range(len(history_encoder_hidden_dims)):
if l == len(history_encoder_hidden_dims) - 1:
history_encoder_layers.append(
nn.Linear(history_encoder_hidden_dims[l], num_latent_dims))
else:
history_encoder_layers.append(
nn.Linear(history_encoder_hidden_dims[l], history_encoder_hidden_dims[l + 1]))
history_encoder_layers.append(activation)
self.history_encoder = nn.Sequential(*history_encoder_layers)
elif history_encoder_type == "TCN":
in_channels = 1
for l in range(len(history_encoder_channel_dims)):
out_channels = history_encoder_channel_dims[l]
padding = history_encoder_dilation[l]*(kernel_size-1)// 2
history_encoder_layers.append(
nn.Conv1d(in_channels, out_channels, kernel_size,
stride=history_encoder_stride[l],
padding=padding,
dilation=history_encoder_dilation[l])
)
in_channels = out_channels
num_history_encoder_input = (num_history_encoder_input - 1) // history_encoder_stride[l] + 1
history_encoder_output_layer = nn.Linear(
num_history_encoder_input * history_encoder_channel_dims[-1], history_encoder_final_layer_dim)
history_encoder_output_activation = activation
history_encoder_latent_layer = nn.Linear(
history_encoder_final_layer_dim, num_latent_dims)
history_encoder_layers.append(nn.Flatten())
history_encoder_layers.append(history_encoder_output_layer)
history_encoder_layers.append(history_encoder_output_activation)
history_encoder_layers.append(history_encoder_latent_layer)
self.history_encoder = nn.Sequential(*history_encoder_layers)
In training, we update the privilege encoder through reinforcement learning and update the history encoder through supervised learning:
loss = surrogate_loss + self.value_loss_coef * \
value_loss - self.entropy_coef * entropy_batch.mean()
# Gradient step
self.optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(
self.actor_critic.parameters(), self.max_grad_norm)
self.optimizer.step()
# history encoder gradient step
for _ in range(self.num_encoder_epochs):
if self.actor_critic.history_encoder_type == "TCN":
if obs_histories_batch.dim() == 2:
# input shape (batch_size, obs_history_len) -> (batch_size, 1, obs_history_len)
obs_histories_batch = obs_histories_batch.unsqueeze(1)
encoder_predictions = self.actor_critic.history_encoder(obs_histories_batch)
with torch.no_grad(): # don't backpropagate through the encoder targets
encoder_targets = self.actor_critic.privilege_encoder(privileged_obs_batch)
encoder_loss = nn.functional.mse_loss( # use mse loss
encoder_predictions, encoder_targets)
self.history_encoder_optimizer.zero_grad()
encoder_loss.backward()
self.history_encoder_optimizer.step()
Asymmetric Actor Critic(A2C)#
To bridge sim-to-real gap, we usually add noise to the observation of actor. If we give the same observation to the critic, then the critic has to estimate the value from noisy observation, which is difficult. Instead, we can give critic noise-free privilege state obtained from simulation so that it can estimate the value more precisely. This aymmetric actor critic(A2C) architecture won’t hinder sim-to-real transfer because the critic network will only function in simulation.
In go2_ts.py, we use two buffers for critic_obs(input of the critic network) and privilege_obs(input of the privilege encoder) separately.
# In go2_ts.py
def compute_observations(self):
self.obs_buf = torch.cat((
self.commands[:, :3] * self.commands_scale, # 3
self.simulator.projected_gravity, # 3
self.simulator.base_ang_vel * self.obs_scales.ang_vel, # 3
(self.simulator.dof_pos - self.simulator.default_dof_pos) *
self.obs_scales.dof_pos, # num_dofs
self.simulator.dof_vel * self.obs_scales.dof_vel, # num_dofs
self.actions # num_actions
), dim=-1)
domain_randomization_info = torch.cat((
(self.simulator._friction_values -
self.friction_value_offset), # 1
self.simulator._added_base_mass, # 1
self.simulator._base_com_bias, # 3
self.simulator._rand_push_vels[:, :2], # 2
(self.simulator._kp_scale -
self.kp_scale_offset), # num_actions
(self.simulator._kd_scale -
self.kd_scale_offset), # num_actions
self.simulator._joint_armature, # 1
self.simulator._joint_stiffness, # 1
self.simulator._joint_damping, # 1
), dim=-1)
# Critic observation
critic_obs = torch.cat((
self.obs_buf, # num_observations
domain_randomization_info, # 34
), dim=-1)
if self.cfg.asset.obtain_link_contact_states:
critic_obs = torch.cat(
(
critic_obs, # previous
self.simulator.link_contact_states, # contact states of thighs, calfs and feet (4+4+4)=12
),
dim=-1,
)
if self.cfg.terrain.measure_heights: # 81
heights = torch.clip(self.simulator.base_pos[:, 2].unsqueeze(
1) - 0.5 - self.simulator.measured_heights, -1, 1.) * self.obs_scales.height_measurements
critic_obs = torch.cat((critic_obs, heights), dim=-1)
self.critic_obs_deque.append(critic_obs)
self.critic_obs_buf = torch.cat(
[self.critic_obs_deque[i]
for i in range(self.critic_obs_deque.maxlen)],
dim=-1,
)
# add noise if needed
if self.add_noise:
self.obs_buf += (2 * torch.rand_like(self.obs_buf) -
1) * self.noise_scale_vec
# push obs_buf to obs_history
self.obs_history_deque.append(self.obs_buf)
self.obs_history = torch.cat(
[self.obs_history_deque[i]
for i in range(self.obs_history_deque.maxlen)],
dim=-1,
)
# Privileged observation, for privileged encoder
if self.num_privileged_obs is not None:
self.privileged_obs_buf = torch.cat(
(
domain_randomization_info, # 34
self.simulator.height_around_feet.flatten(1,2), # 9*number of feet
self.simulator.normal_vector_around_feet, # 3*number of feet
),
dim=-1,
)
if self.cfg.asset.obtain_link_contact_states:
self.privileged_obs_buf = torch.cat(
(
self.privileged_obs_buf, # previous
self.simulator.link_contact_states, # contact states of thighs, calfs and feet (4+4+4)=12
),
dim=-1,
)
Ablation of TCN(Temporal Convolutional Network)#
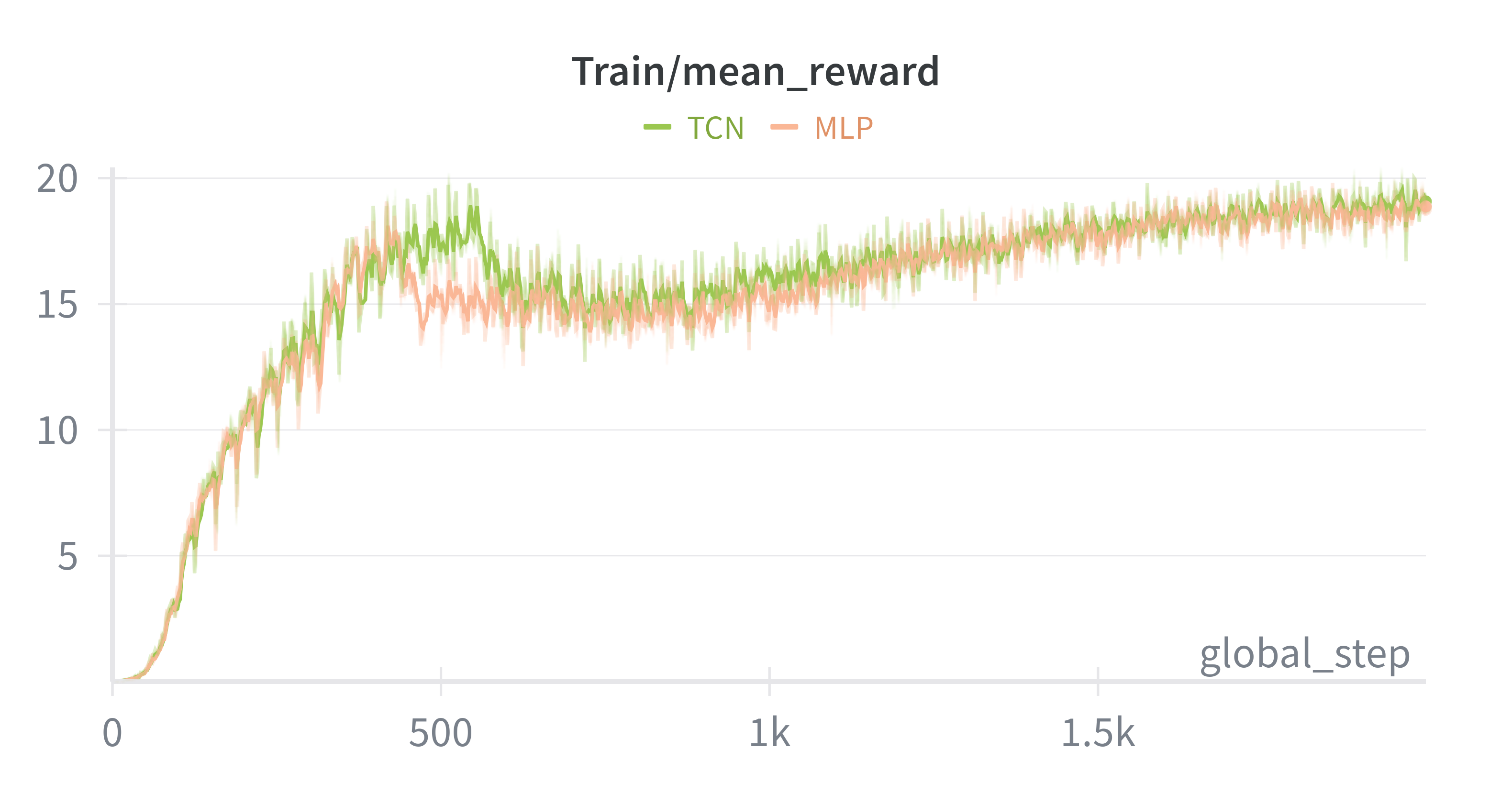
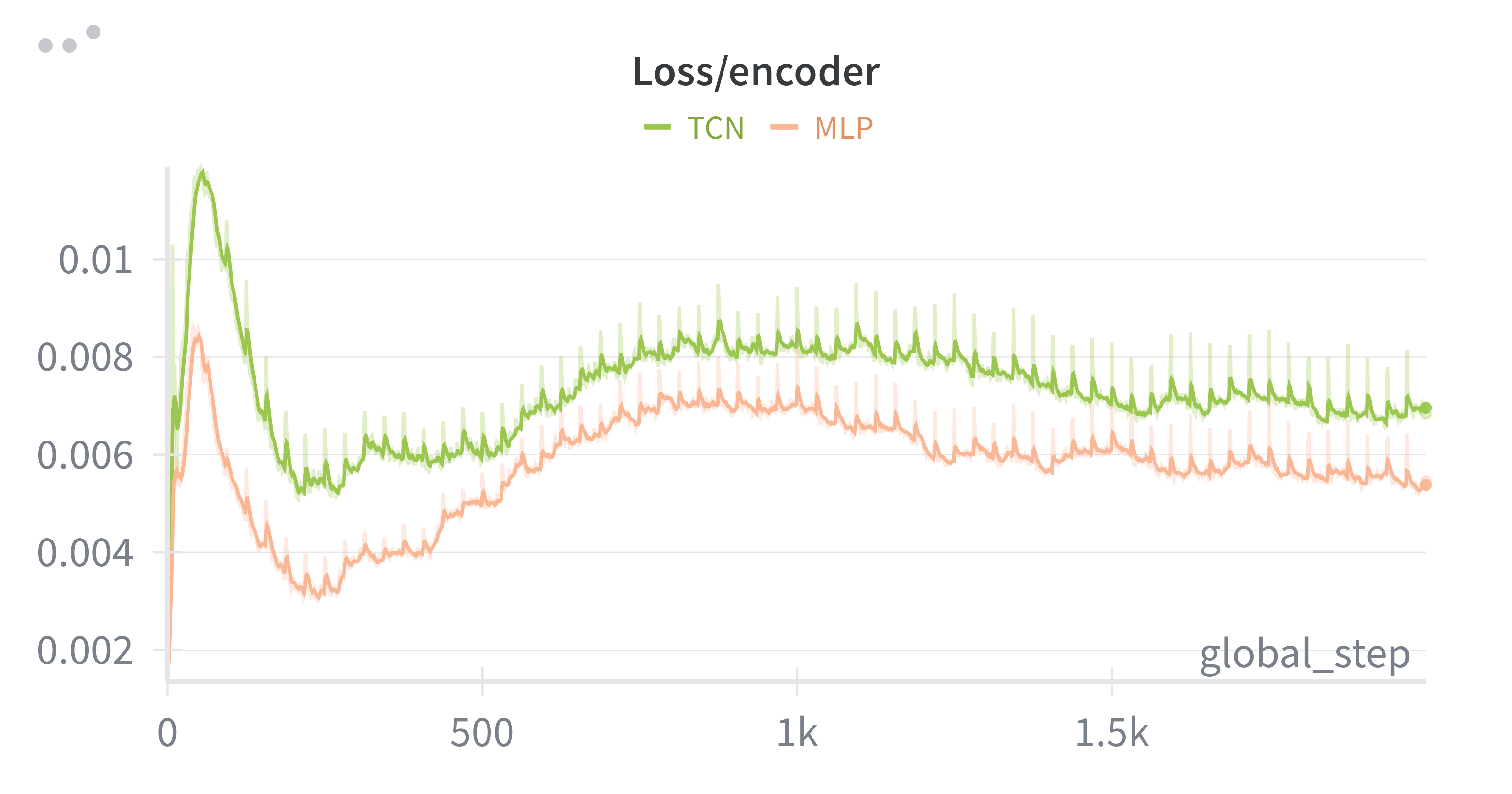
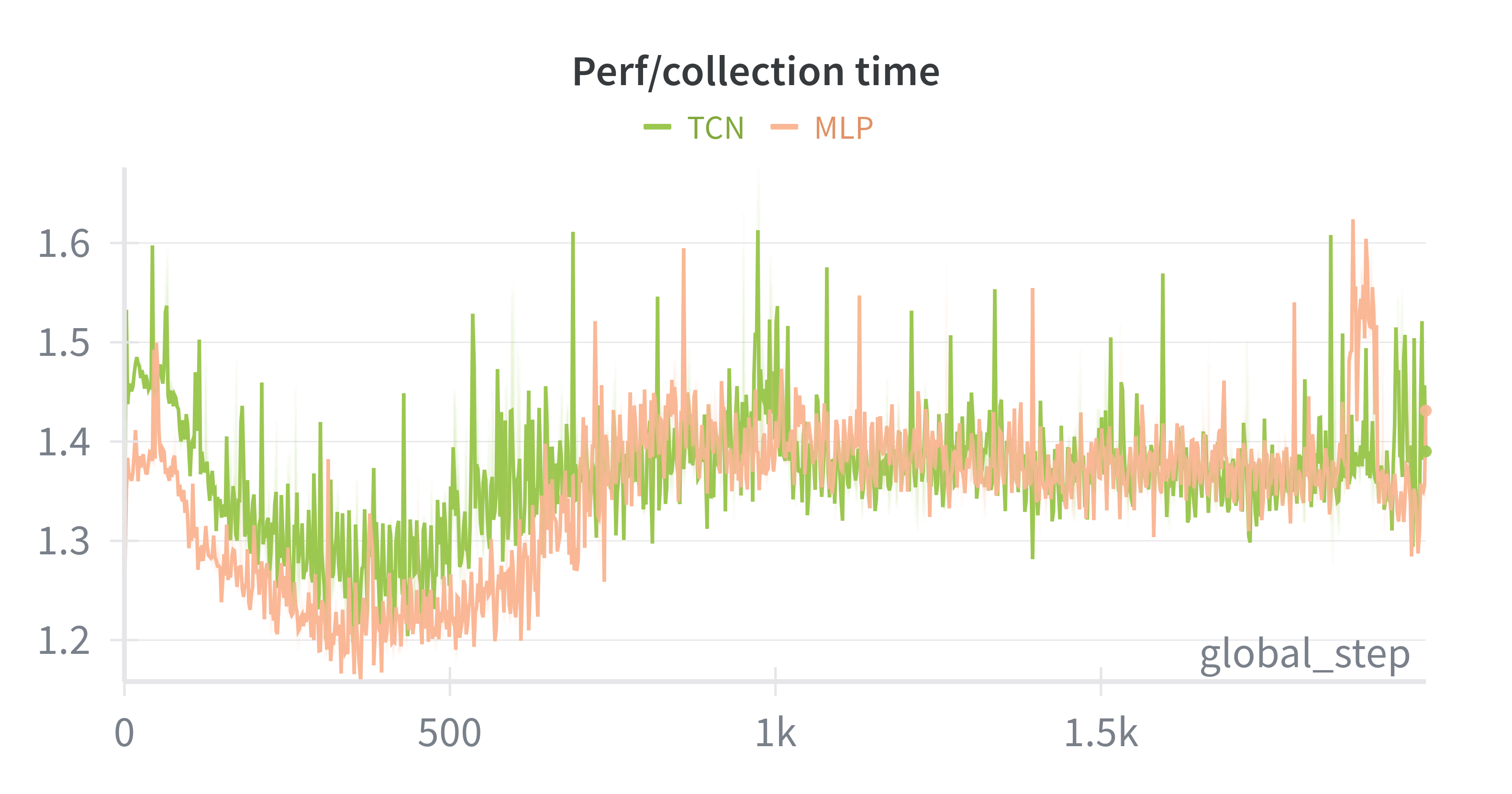
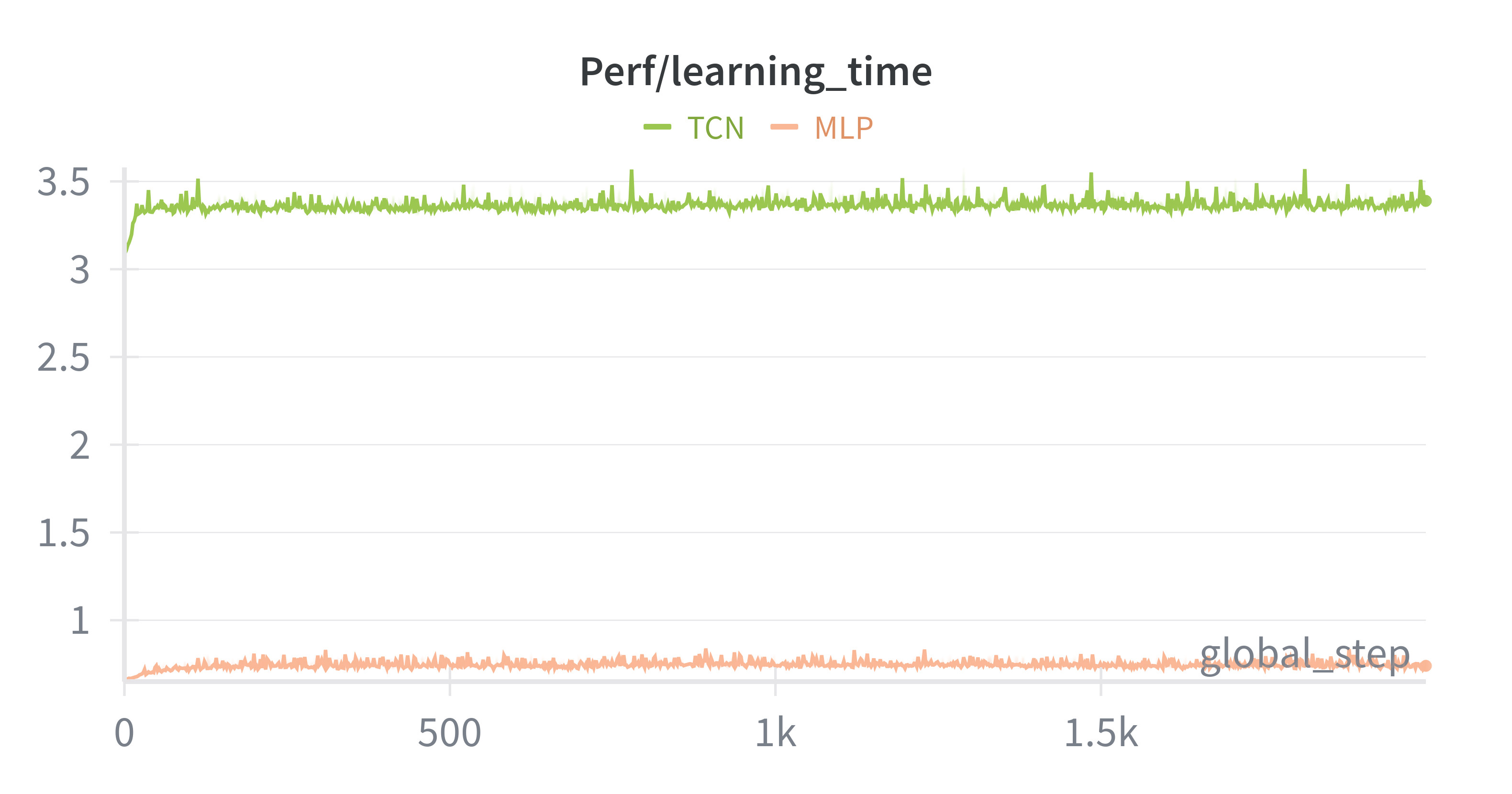
In the original teacher-student paper, authors used TCN as the body of student encoder and compared its computation efficiency with GRU. Here we did an ablation study of TCN to see whether using TCN can bring lower prediction loss and faster training speed. We set history length to 100(corresponds to a history window of 2s). As shown in below two figures, we can see that the total reward is almost the same, but the encoder loss(i.e. prediction loss) of TCN is larger. Meanwhile, the collection_time(time to collect data for one iteration) of both are the same, yet the learning_time(time to update neural networks) of TCN is nearly five times as much as that of MLP. These results explain the superiority of MLP over TCN in this context.
Cocurrent Teacher-Student#
The biggest drawback of simple teacher-student framework is the distribution shift between teacher and student policies. And because the student policy is trained through Supervised learning but reinforcement learning, it is prone to out-of-distribution (OOD), which will lead to undesired behaviors in the student policy.
To solve this shorcoming, researchers proposed CTS (Cocurrent Teacher Student) framework. The idea of this framework is to let the gradient flow through the path of student encoder -> policy besides the teacher encoder -> policy flow. This is achieved by seperating all environments into two groups and consider the surrogate losses of them. Using this method, the robustness of the resultant student policy can be enhanced. The implementation of CTS provided by us can be found in ppo_cts.
Train and Play#
To train a teacher-student policy, type the following command:
python train.py --task=go2_ts --headless
To play it, type the following command:
python play.py --task=go2_ts --load_run=session_name
For training a cts policy, you only need to substitute the ts in task name with cts.
Demostration#
We have provided reference deployment code of student policy trained by Teacher-Student in go2_deploy.
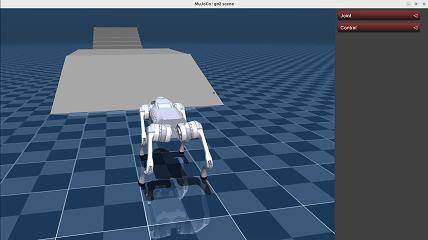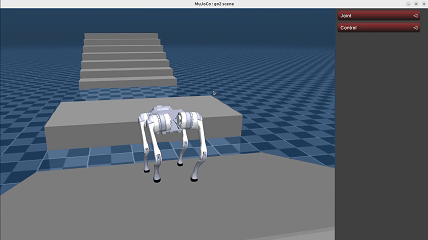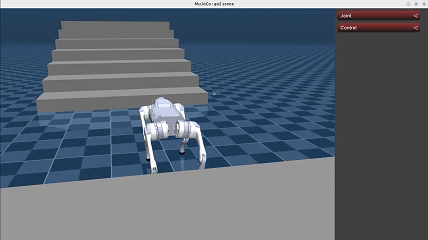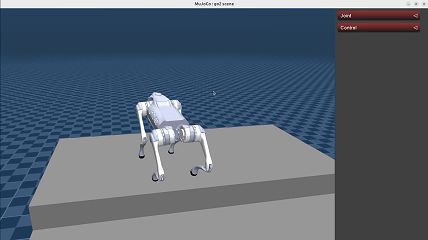
Here we show the demo of running a policy trained using teacher-student framework with a history length of 20.