⏱️ Explicit Estimator#
In teacher_student framework, the latent vector output by the teacher encoder is an encoded information of privileged information \(x_t\). The latent vector is some kind of representation of the privileged information, without explicit physical meaning. However, according to our experience in Deploy to Real Robot, the existence of base_lin_vel can improve the performance of the agent significantly. Then the problem is how can we obtain base_lin_vel in the real robot.
From the perspective of model-based control, Kalman Filter can help us estimate base_lin_vel using feedback of robot states. However, this kind of method usually relies on some assumption, limiting their versatility. With the great power of neural network, how can we handle it? EstimatorNet was proposed to solve this.
Framework Analysis#
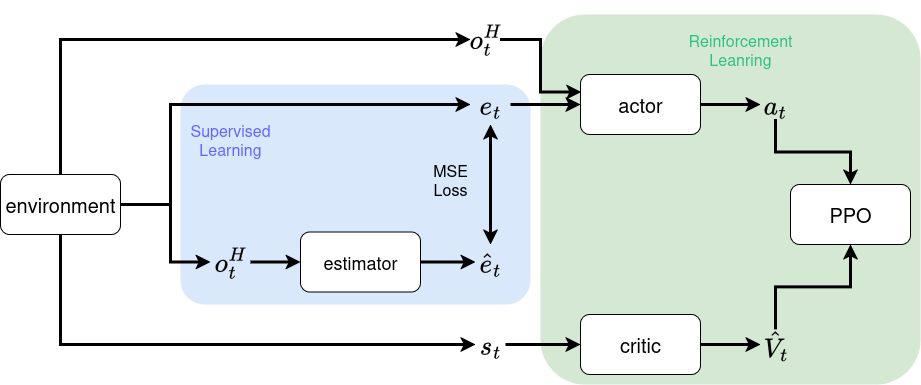
Basically, EstimatorNet has the similar form of diagram with teacher-student framework. The biggest difference is that the encoder output in EstimatorNet is trained to approximate explicit physical values, such as base linear velocity, foot contact probability, foot height and so on. The diagram of EstimatorNet is shown as below, where \(e_t\) is true value of explicit vector, \(o_t^H=[o_t, o_{t-1},...,o_{t-H+1}]\) is observation history with length of H steps, \(\hat{e}_t\) is predicted explicit vector from estimator network, \(a_t\) is the action, \(s_t\) is the state of the environment, \(\hat{V}_t\) is the estimated value from the critic.
Implementation#
The implementation of this method is similar with teacher_student framework. Readers can look through files with suffix of ee to find the implementation.
To train a explicit estimator policy, type the following command:
python train.py --task=go2_ee --headless
To play it, type the following command:
python play.py --task=go2_ee --load_run=session_name
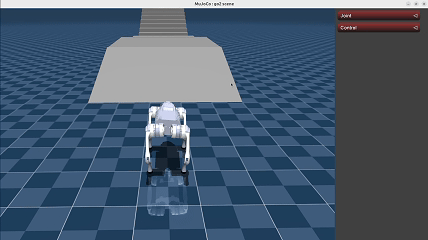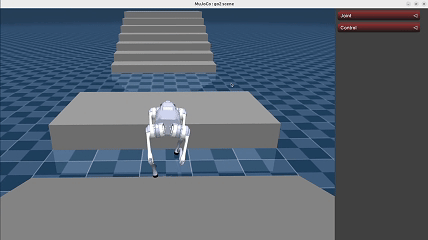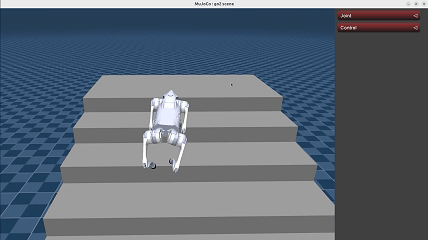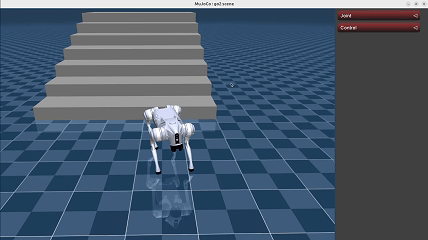
Demonstration#
We have provided reference deployment code of explicit estimator policy in go2_deploy_python and tron1_rl_deploy_python.
Unitree Go2:
TRON1_PF: