⛕ Walk These Ways#
As stated by Margolis \( \textit{et al.}^{1}\), the multiplicity of behavior (MoB) can help the robot generalize in different ways. The basic idea of \( \textit{Walk These Ways} \) is to learn different behaviors on the flat ground and tune the behavior through high-level decision (which is human operator in this paper).
To incoporate different behaviors into one NN, we essentially want to achieve multi-task reinforcement learning. Key components in this implementation consist of three parts:
Task-related observation
Task rewards
Reward-based Curriculum
Task-related Observation#
To enable the neural network policy to distinguish between different behaviors, we need to provide observation related to the task as an input.
In our implementation, our interested behavior include gait_period, base_height, foot_clearance, base_pitch and gait_type. For the first four behavior, we just place the parameter directly into the observation. For the gait_type, we use theta (phase offset of four feet) combined with clock_input to represent different gait types:
# In go2_wtw.py
def compute_observations(self):
""" Computes observations
"""
obs_buf = torch.cat((
self.commands[:, :3] * self.commands_scale, # cmd 3
self.simulator.projected_gravity, # g 3
self.simulator.base_ang_vel * self.obs_scales.ang_vel, # omega 3
(self.simulator.dof_pos - self.simulator.default_dof_pos) *
self.obs_scales.dof_pos, # p_t 12
self.simulator.dof_vel * self.obs_scales.dof_vel, # dp_t 12
self.actions, # a_{t-1} 12
self.clock_input, # clock 4
self.gait_period, # gait period 1
self.base_height_target, # base height target 1
self.foot_clearance_target, # foot clearance target 1
self.pitch_target, # pitch target 1
self.theta, # theta, gait offset, 4
), dim=-1)
...
Here, the gait specification method we use is based on the principle in Siekmann \(\textit{et al.}\). Building upon their principle, we provide an extra step function implementaion to construct gait indicators:
# In go2_wtw.py
def _uniped_periodic_gait(self, foot_type):
# q_frc and q_spd
if foot_type == "FL":
q_frc = torch.norm(
self.simulator.link_contact_forces[:,
self.simulator.feet_indices[0], :], dim=-1).view(-1, 1)
q_spd = torch.norm(
self.simulator.feet_vel[:, 0, :], dim=-1).view(-1, 1) # sequence of feet_pos is FL, FR, RL, RR
# size: num_envs; need to reshape to (num_envs, 1), or there will be error due to broadcasting
# modulo phi over 1.0 to get cicular phi in [0, 1.0]
phi = (self.phi + self.theta[:, 0].unsqueeze(1)) % 1.0
elif foot_type == "FR":
q_frc = torch.norm(
self.simulator.link_contact_forces[:,
self.simulator.feet_indices[1], :], dim=-1).view(-1, 1)
q_spd = torch.norm(
self.simulator.feet_vel[:, 1, :], dim=-1).view(-1, 1)
# modulo phi over 1.0 to get cicular phi in [0, 1.0]
phi = (self.phi + self.theta[:, 1].unsqueeze(1)) % 1.0
elif foot_type == "RL":
q_frc = torch.norm(
self.simulator.link_contact_forces[:,
self.simulator.feet_indices[2], :], dim=-1).view(-1, 1)
q_spd = torch.norm(
self.simulator.feet_vel[:, 2, :], dim=-1).view(-1, 1)
# modulo phi over 1.0 to get cicular phi in [0, 1.0]
phi = (self.phi + self.theta[:, 2].unsqueeze(1)) % 1.0
elif foot_type == "RR":
q_frc = torch.norm(
self.simulator.link_contact_forces[:,
self.simulator.feet_indices[3], :], dim=-1).view(-1, 1)
q_spd = torch.norm(
self.simulator.feet_vel[:, 3, :], dim=-1).view(-1, 1)
# modulo phi over 1.0 to get cicular phi in [0, 1.0]
phi = (self.phi + self.theta[:, 3].unsqueeze(1)) % 1.0
phi *= 2 * torch.pi # convert phi to radians
if self.gait_function_type == "smooth":
# coefficient
c_swing_spd = 0 # speed is not penalized during swing phase
c_swing_frc = -1 # force is penalized during swing phase
c_stance_spd = -1 # speed is penalized during stance phase
c_stance_frc = 0 # force is not penalized during stance phase
# clip the value of phi to [0, 1.0]. The vonmises function in scipy may return cdf outside [0, 1.0]
F_A_swing = torch.clip(torch.tensor(vonmises.cdf(loc=self.a_swing,
kappa=self.kappa, x=phi.cpu()), device=self.device), 0.0, 1.0)
F_B_swing = torch.clip(torch.tensor(vonmises.cdf(loc=self.b_swing.cpu(),
kappa=self.kappa, x=phi.cpu()), device=self.device), 0.0, 1.0)
F_A_stance = F_B_swing
F_B_stance = torch.clip(torch.tensor(vonmises.cdf(loc=self.b_stance,
kappa=self.kappa, x=phi.cpu()), device=self.device), 0.0, 1.0)
# calc the expected C_spd and C_frc according to the formula in the paper
exp_swing_ind = F_A_swing * (1 - F_B_swing)
exp_stance_ind = F_A_stance * (1 - F_B_stance)
exp_C_spd_ori = c_swing_spd * exp_swing_ind + c_stance_spd * exp_stance_ind
exp_C_frc_ori = c_swing_frc * exp_swing_ind + c_stance_frc * exp_stance_ind
# just the code above can't result in the same reward curve as the paper
# a little trick is implemented to make the reward curve same as the paper
# first let all envs get the same exp_C_frc and exp_C_spd
exp_C_frc = -0.5 + (-0.5 - exp_C_spd_ori)
exp_C_spd = exp_C_spd_ori
# select the envs that are in swing phase
is_in_swing = (phi >= self.a_swing) & (phi < self.b_swing)
indices_in_swing = is_in_swing.nonzero(as_tuple=False).flatten()
# update the exp_C_frc and exp_C_spd of the envs in swing phase
exp_C_frc[indices_in_swing] = exp_C_frc_ori[indices_in_swing]
exp_C_spd[indices_in_swing] = -0.5 + \
(-0.5 - exp_C_frc_ori[indices_in_swing])
# Judge if it's the standing gait
is_standing = (self.b_swing[:] == self.a_swing).nonzero(
as_tuple=False).flatten()
exp_C_frc[is_standing] = 0
exp_C_spd[is_standing] = -1
elif self.gait_function_type == "step":
''' ***** Step Gait Indicator ***** '''
exp_C_frc = torch.zeros(self.num_envs, 1, dtype=torch.float, device=self.device)
exp_C_spd = torch.zeros(self.num_envs, 1, dtype=torch.float, device=self.device)
swing_indices = (phi >= self.a_swing) & (phi < self.b_swing)
swing_indices = swing_indices.nonzero(as_tuple=False).flatten()
stance_indices = (phi >= self.b_swing) & (phi < self.b_stance)
stance_indices = stance_indices.nonzero(as_tuple=False).flatten()
exp_C_frc[swing_indices, :] = -1
exp_C_spd[swing_indices, :] = 0
exp_C_frc[stance_indices, :] = 0
exp_C_spd[stance_indices, :] = -1
return exp_C_spd * q_spd + exp_C_frc * q_frc, \
exp_C_spd.type(dtype=torch.float), exp_C_frc.type(dtype=torch.float)
def _reward_quad_periodic_gait(self):
quad_reward_fl, self.exp_C_spd_fl, self.exp_C_frc_fl = self._uniped_periodic_gait(
"FL")
quad_reward_fr, self.exp_C_spd_fr, self.exp_C_frc_fr = self._uniped_periodic_gait(
"FR")
quad_reward_rl, self.exp_C_spd_rl, self.exp_C_frc_rl = self._uniped_periodic_gait(
"RL")
quad_reward_rr, self.exp_C_spd_rr, self.exp_C_frc_rr = self._uniped_periodic_gait(
"RR")
# reward for the whole body
quad_reward = quad_reward_fl.flatten() + quad_reward_fr.flatten() + \
quad_reward_rl.flatten() + quad_reward_rr.flatten()
return torch.exp(quad_reward)
One can choose to use either gait_function_type (specified in go2_wtw_config.py). Below are curves of exp_C_frc using smooth_function(kappa=20) and step_function:
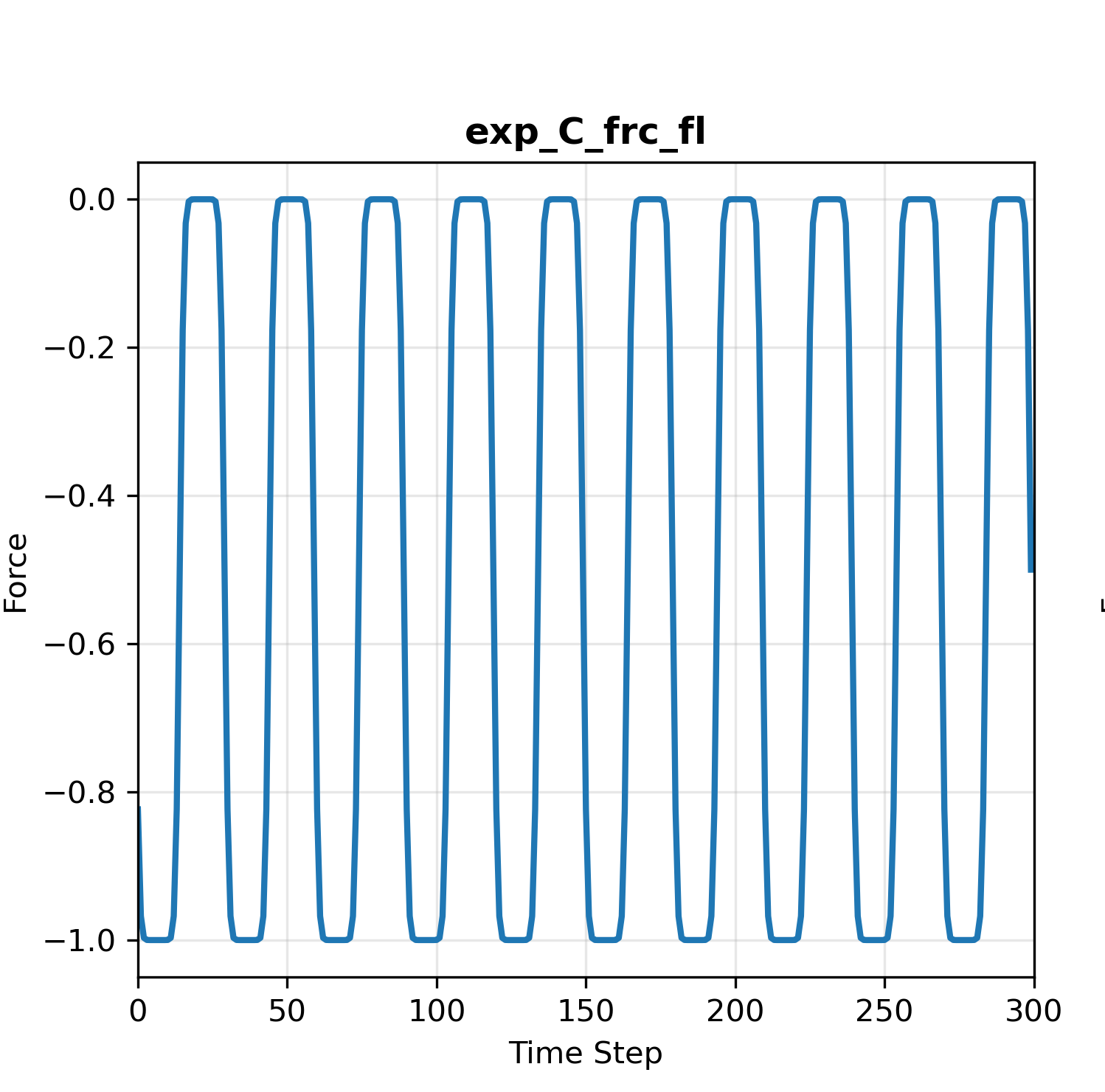
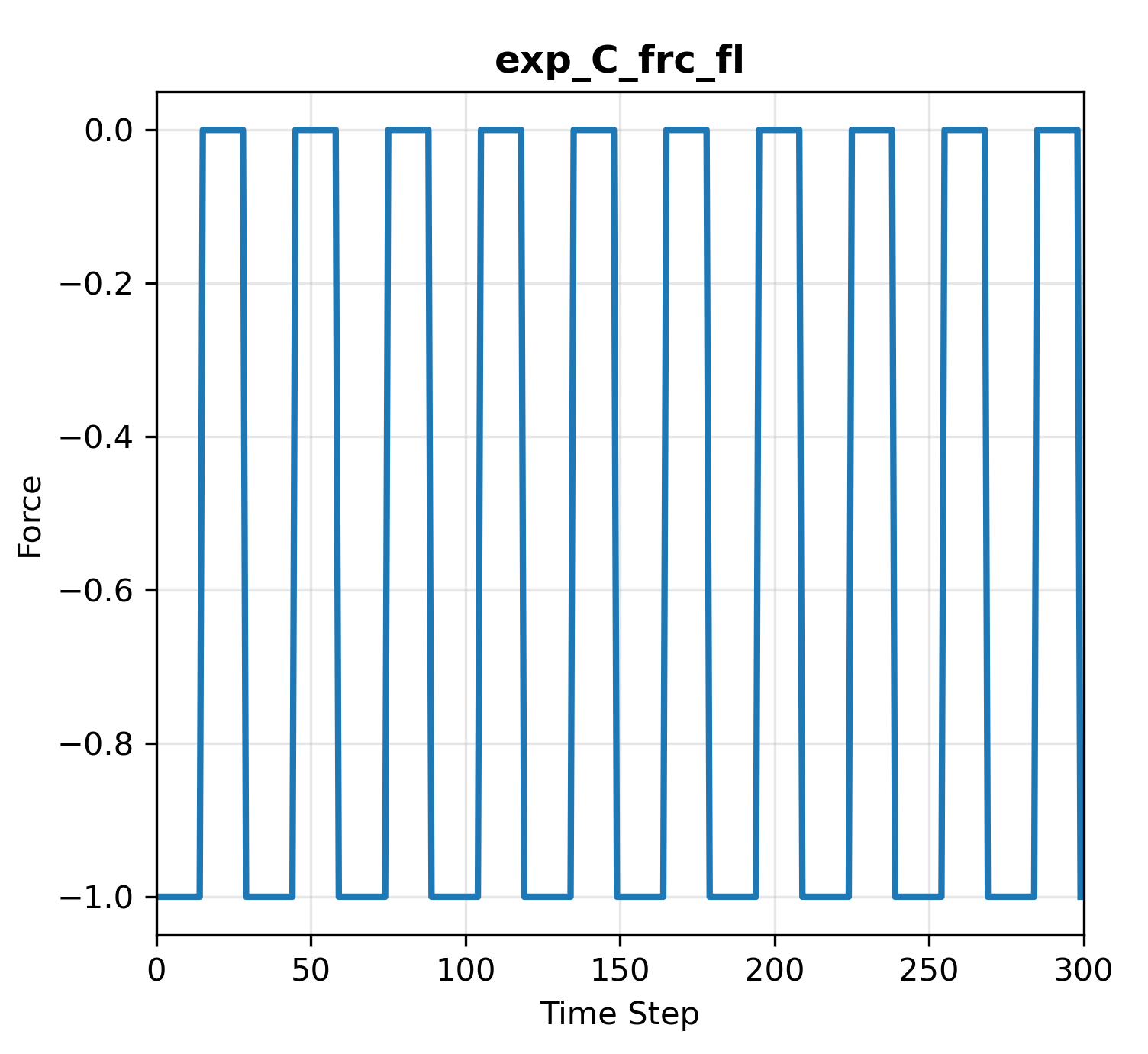
Based on our practice, there’s no much difference in terms of gait tracking performance between step function and smooth function.
Task Rewards#
To guide the policy to optimize towards the direction of achieving desired behavior, we need to construct rewards incorporating behavior parameters.
For our implementation, behavior task rewards include _reward_quad_periodic_gait, _reward_tracking_base_height, _reward_tracking_orientation and _reward_tracking_foot_clearance. Readers can refer to go2_wtw.py for line-by-line codes.
Reward-based Curriculum#
As stated by Rudin \(\textit{et al.}^{3}\), proper curriculum design can foster the learning process and help the robot learn more difficult behavior. We implement a reward-based curriculum similar to legged_gym to enlarge the range of behavior parameters only if the policy has mastered the behavior well enough in the current range:
def _update_behavior_param_curriculum(self, env_ids):
if len(env_ids) == 0:
return
# Widen the behavior param range according to reward values
if torch.mean(self.episode_sums["quad_periodic_gait"][env_ids]) / \
self.max_episode_length > 0.8 * self.reward_scales["quad_periodic_gait"]: # 0.8 for step gait, 0.5 for smooth gait
# gait period
self.gait_period_range[0] = max(self.gait_period_range[0] - 0.05, self.gait_period_min)
self.gait_period_range[1] = min(self.gait_period_range[1] + 0.05, self.gait_period_max)
# gait number
self.num_gaits = min(self.num_gaits + 1, self.num_gait_max)
if torch.mean(self.episode_sums["tracking_base_height"][env_ids]) / \
self.max_episode_length > 0.9 * self.reward_scales["tracking_base_height"]:
self.base_height_target_range[0] = max(self.base_height_target_range[0] - 0.02, self.base_height_target_min)
self.base_height_target_range[1] = min(self.base_height_target_range[1] + 0.02, self.base_height_target_max)
if torch.mean(self.episode_sums["tracking_foot_clearance"][env_ids]) / \
self.max_episode_length > 0.8 * self.reward_scales["tracking_foot_clearance"]:
self.foot_clearance_target_range[0] = max(self.foot_clearance_target_range[0] - 0.01,
self.foot_clearance_target_min)
self.foot_clearance_target_range[1] = min(self.foot_clearance_target_range[1] + 0.01,
self.foot_clearance_target_max)
if torch.mean(self.episode_sums["tracking_orientation"][env_ids]) / \
self.max_episode_length > 0.9 * self.reward_scales["tracking_orientation"]:
self.pitch_target_range[0] = max(self.pitch_target_range[0] - 0.05, self.pitch_target_min)
self.pitch_target_range[1] = min(self.pitch_target_range[1] + 0.05, self.pitch_target_max)
Train and Play#
To train a walk these ways policy, type the following command:
python train.py --task=go2_wtw --headless
To play it, type the following command:
python play.py --task=go2_wtw --load_run=session_name
Demonstration#
We provide an implementation of \( \textit{Walk These Ways} \) in go2_deploy, you can run it using the following command:
./go2_deploy wtw
The demo video is as follows: